DAVID
GONZALEZ
Data Scientist
Handwritten Digit Recognition with MLOps
MLOps
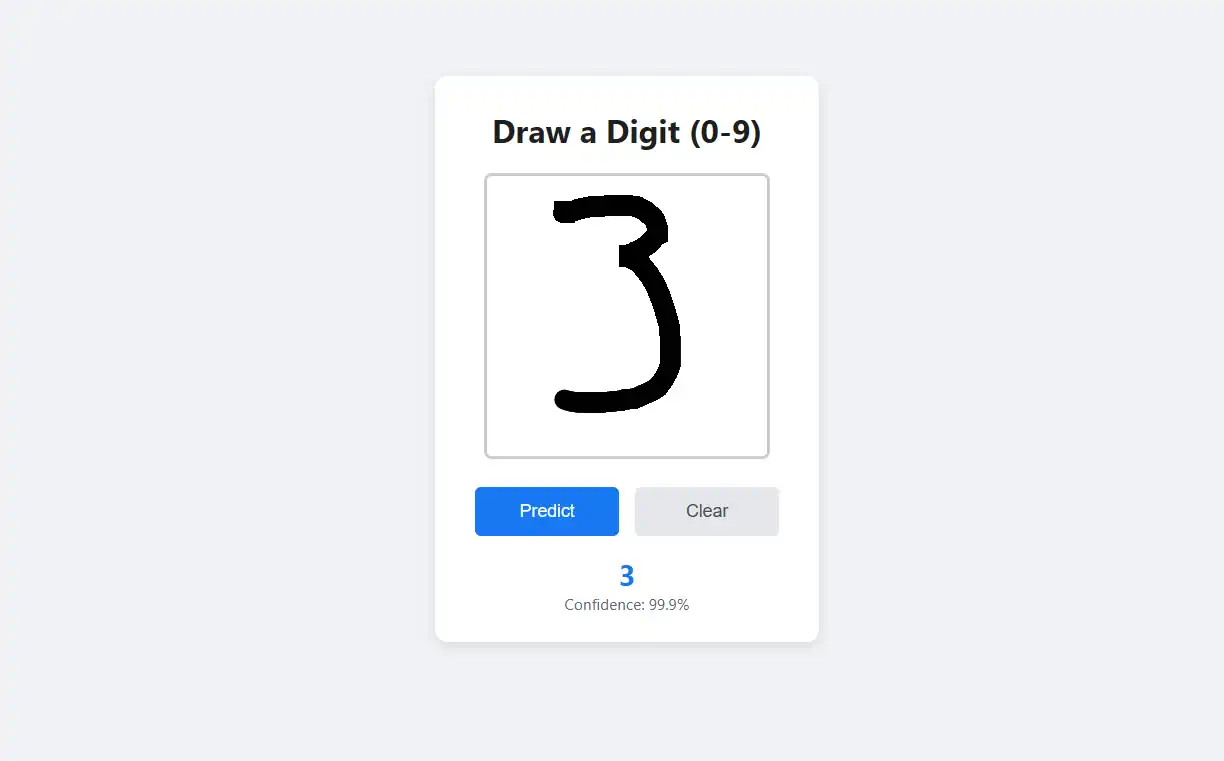
Project Overview
Production-grade machine learning system that can accurately recognize handwritten digits in real-world conditions with 98.63% accuracy. Built from scratch using 21,000+ European handwritten digit images, this end-to-end project demonstrates professional ML engineering, from data preprocessing and CNN training to REST API deployment and interactive web interface. Unlike typical academic exercises, this system is containerized, production-ready, and serves real-time predictions in under 100ms.
Challenge
The challenge wasn't just achieving high accuracy, it was engineering a complete production system. Specific obstacles included: (1) transforming 21,000+ heterogeneous Swiss handwritten digit images into a clean, MNIST-compatible dataset through robust preprocessing, (2) eliminating train-test mismatch by ensuring inference preprocessing perfectly replicates training preprocessing, (3) building a production-ready API, and (4) containerizing the entire stack for reproducible deployment.
Approach
Data Engineering: Designed a 5-step preprocessing
pipeline (grayscale → LANCZOS resize to 28x28 → color inversion
→ normalization) that transforms raw images into MNIST
format.
Model Architecture: Built a 3-layer CNN with batch
normalization, dropout regularization, and strategic callbacks
(EarlyStopping, ReduceLROnPlateau, ModelCheckpoint)
Backend Development: Implemented FastAPI with dependency
injection for model loading, Pydantic for request/response
validation, environment-based configuration (dev/prod/test
modes), and structured error handling.
Results & Impact
- 98.63% test accuracy on 21,000+ image dataset
- >100ms inference time per prediction
- lightweight and efficient
- Zero train-test mismatch through identical preprocessing pipelines
Gallery

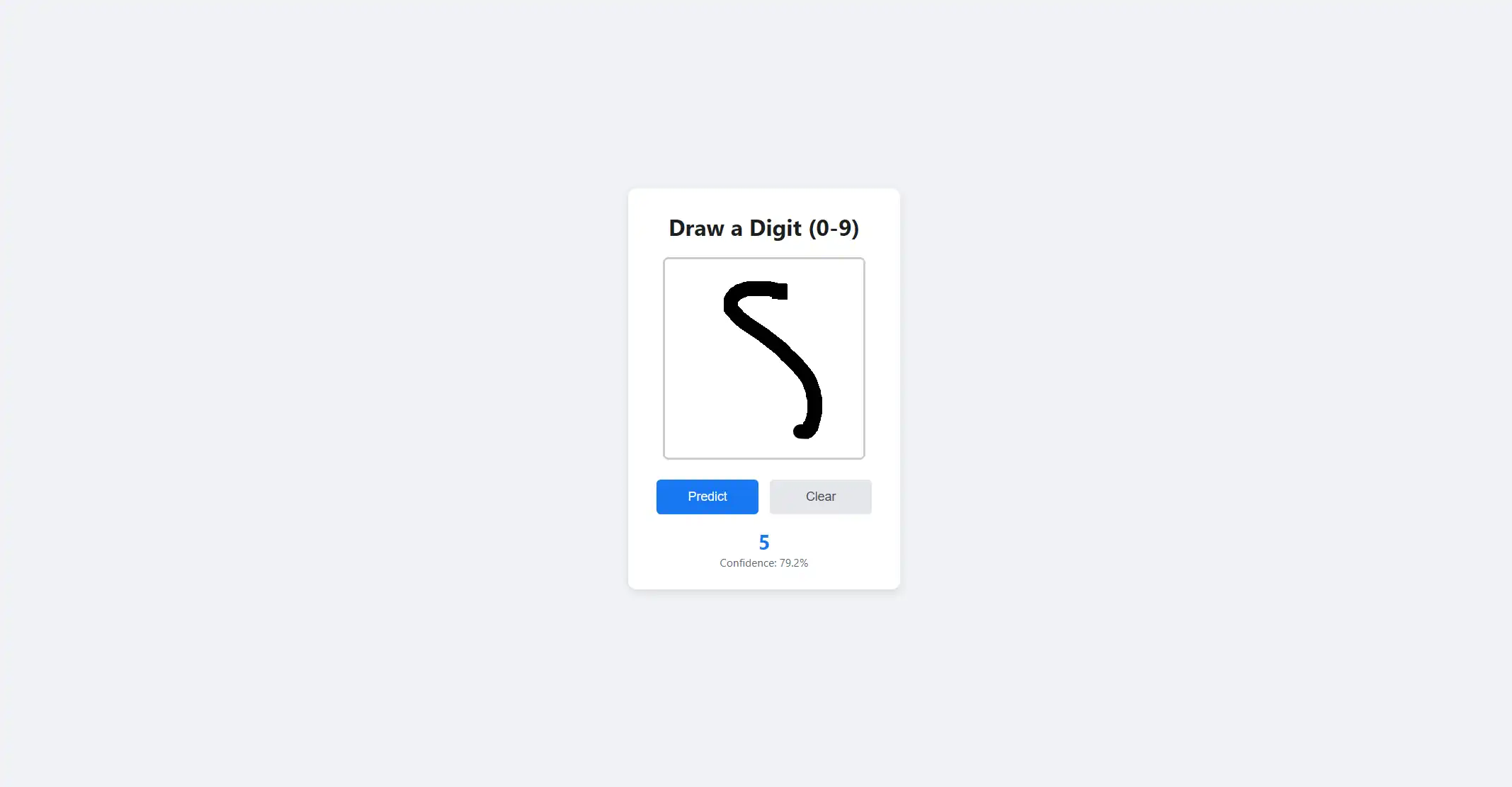
Key Features
- Zero Train-Test Mismatch Architecture
- Production-Ready REST API
- Fully Containerized Deployment
Lessons Learned
The biggest lesson was realizing that model accuracy depends as much on data engineering as on architecture. Investing time upfront to build a robust 5-step preprocessing pipeline was crucial. The breakthrough came when I stopped trying to "improve" the inference preprocessing and instead focused on perfectly replicating the training pipeline
Future Improvements
- Extend the system to recognize sequences of digits (like house numbers or postal codes) by implementing digit segmentation